AI Document Intelligence System
A high-fidelity prototype demonstrating how a 'database-as-UI' can power a dynamic, self-populating knowledge base from unstructured documents.

A high-fidelity prototype demonstrating how a 'database-as-UI' can power a dynamic, self-populating knowledge base from unstructured documents.
A prestigious law and accounting firm was struggling with a critical inefficiency: their team was spending countless hours processing complex client documents. Legal deeds, financial statements, and contracts arrived as lengthy PDFs, locking away vital information.
Professionals had to manually read through every document to find specific data points like names, dates, amounts, or key clauses, and then meticulously enter them into their Baserow database. Furthermore, if a new data requirement emerged, there was no efficient way to go back and extract this new information from hundreds of existing documents.
Paralegals and accountants manually scanned PDFs, searched for key data, and copy-pasted information into a Baserow table—a slow, error-prone, and costly process.
A 'drag-and-drop' workflow. Users simply upload a PDF to a Baserow row, and an AI assistant automatically reads the document and populates the corresponding columns with the correct information.
The pipeline is activated instantly via webhooks when a user uploads a new document to the database, eliminating the need for manual batch processing.
The system queries the database schema in real-time. It uses column descriptions as dynamic prompts, allowing administrators to add new extraction rules without changing the code.
The architecture securely retrieves the unstructured file and processes it through an OCR and text-extraction layer, preparing it for semantic analysis.
An LLM iterates over the required data points. By injecting the dynamic schema prompts alongside the document text, it performs precise, context-aware data extraction.
Extracted raw text is passed through a sanitization layer to ensure it matches the expected data types (dates, currencies, strings) before database insertion.
The system executes a precise PATCH request to the database, enriching the original record with the structured data in real-time, visible instantly to the user.
The most innovative feature is using Baserow's native 'Description' field for columns as dynamic AI prompts. This empowers non-technical users to configure the AI's extraction tasks without ever leaving their database. To extract new data, they simply add a column and describe what they need.
// Example of how a column description becomes a prompt
{
"field_name": "Contracting Party",
"description": "Extract the full name of the primary company or individual signing this agreement."
}The workflow's intelligence is amplified by its dual-trigger design. While one branch processes new file uploads, a second branch listens for `field.created` events. This demonstrates the concept of retroactive enrichment: adding a new column can trigger a process to analyze the entire document archive.
The workflow utilizes n8n's 'SplitInBatches' node for iteration. In the connection graph visible in the JSON, the first output of this node is intentionally left empty. This is the standard n8n pattern for loop termination; the workflow proceeds from this branch only after all batches have been completed.
This MVP serves as a powerful proof-of-concept. To transition to a production-grade service, the following architecture would be implemented: Webhook Signature Validation for security, a proper Job Queue System (e.g., BullMQ) for handling large-scale retroactive processing, Rate Limiting and Exponential Backoff for API stability, and a dedicated "extraction_status" field in Baserow for robust tracking and retries. The current retroactive branch is a batch demonstrator; the production version would filter for the specific `row_id` from the event payload to process only the relevant document.
This solution transformed the firm’s data management process, converting their Baserow database into an intelligent, self-populating knowledge base. It has eliminated thousands of hours of manual data entry.
The platform is future-proof; new data requirements can be applied retroactively to the entire document archive by simply adding a new column, turning a historical data mining project into a simple UI action.
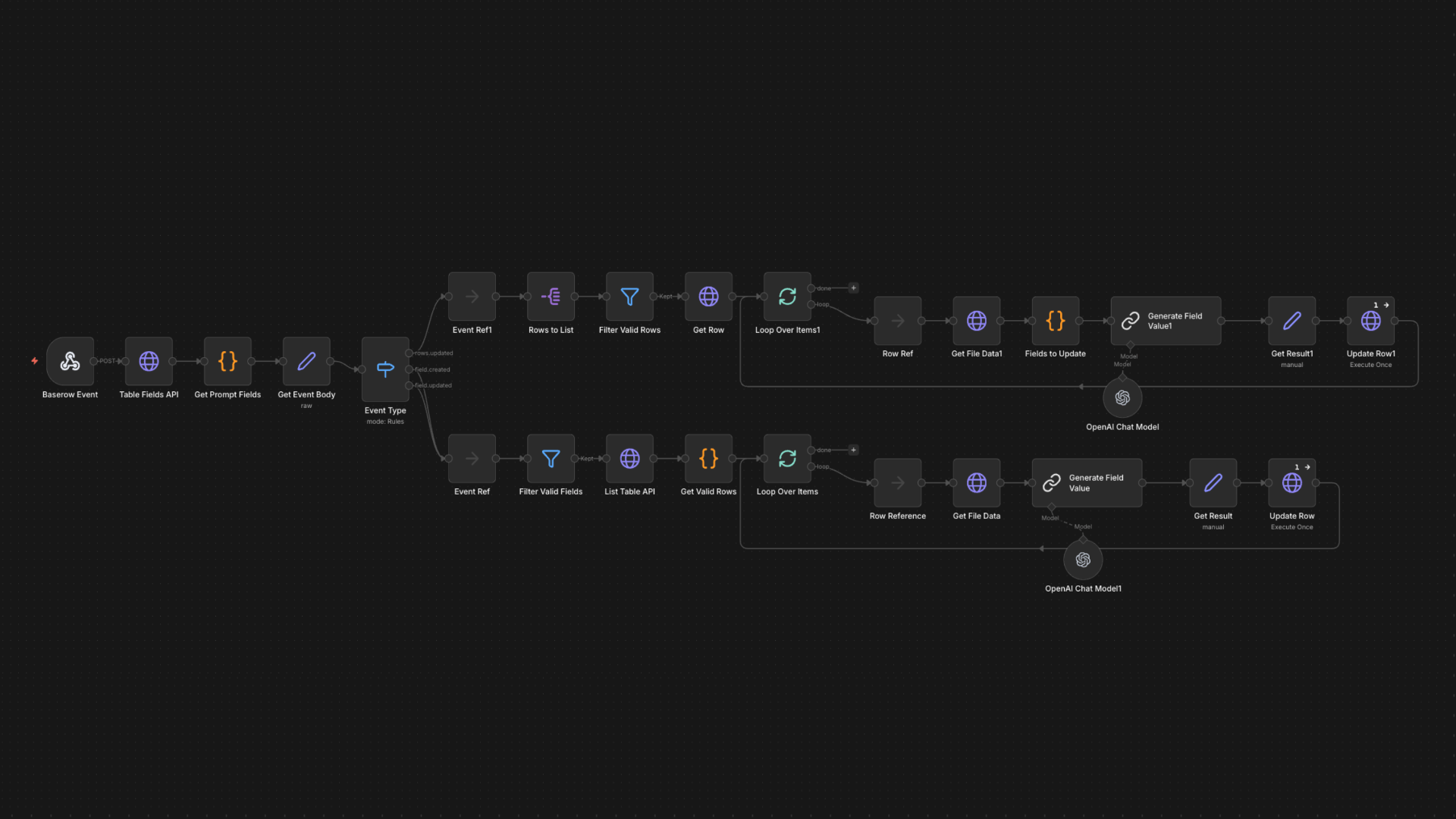
Document Intelligence Pipeline